随着人工智能技术的飞速发展,AI大模型(如GPT、BERT等)已成为推动创新的核心驱动力。AI大模型的网络搭建涉及复杂的硬件、软件和网络架构设计,而相应的网络技术服务则是确保模型高效运行和拓展的关键。本文将系统介绍AI大模型网络搭建的步骤,并探讨网络技术服务的核心内容。
一、AI大模型网络搭建的关键步骤
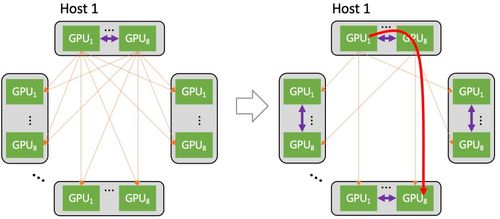
- 硬件基础设施规划:AI大模型需要强大的计算资源,通常采用GPU集群(如NVIDIA A100或H100)来支持训练和推理。网络搭建首先需设计高速互联架构,例如使用InfiniBand或RoCE(RDMA over Converged Ethernet)技术,以减少通信延迟并提升数据传输效率。需确保充足的存储系统,如分布式文件系统或对象存储,以处理海量数据集和模型参数。
- 软件环境配置:搭建网络需部署专用软件栈,包括深度学习框架(如TensorFlow、PyTorch)和分布式训练工具(如Horovod或NCCL)。容器化技术(如Docker和Kubernetes)常用于管理资源,确保模型可伸缩部署。需设置监控和日志系统,实时跟踪网络性能和模型状态。
- 网络架构设计:对于大规模模型,网络拓扑结构至关重要。常见的架构包括星型、环型或混合拓扑,以优化节点间通信。安全措施如防火墙、VPN和加密协议必须集成,防止数据泄露和攻击。网络带宽和延迟需通过负载均衡和流量管理工具进行优化,确保训练过程的稳定性。
- 数据管道与预处理:搭建网络时,需构建高效的数据管道,支持数据的采集、清洗和预处理。这可能涉及与云服务(如AWS或Azure)集成,实现数据流的无缝对接。数据隐私和合规性需通过匿名化或联邦学习技术来处理。
二、网络技术服务在AI大模型中的应用
网络技术服务是AI大模型生命周期中的支撑环节,主要包括:
- 部署与运维服务:提供模型的云端或本地部署,包括自动化脚本、持续集成/持续部署(CI/CD)流程,以及7x24监控服务,确保高可用性和快速故障恢复。
- 性能优化服务:通过网络分析工具(如Wireshark或Prometheus)诊断瓶颈,优化数据传输和计算负载。这可能包括调整网络参数、实施缓存策略或采用边缘计算以减少延迟。
- 安全与合规服务:提供端到端加密、访问控制和漏洞扫描,确保模型和数据在网络传输中的安全。协助满足GDPR、HIPAA等法规要求。
- 可扩展性支持:随着模型规模扩大,网络技术服务可帮助扩展集群规模,采用微服务架构或serverless计算,实现弹性资源分配。
三、实践建议与未来展望
在搭建AI大模型网络时,建议从小规模原型开始,逐步测试网络性能。与专业网络服务提供商合作可加速部署,例如利用云计算平台的托管服务(如Google AI Platform或Azure Machine Learning)。随着5G和6G技术的发展,AI大模型网络将更加高效,网络技术服务也将融入更多AI驱动的自动化工具,实现智能运维。
AI大模型网络搭建是一个多学科集成的过程,而网络技术服务则保障了其可靠性和可扩展性。通过合理规划和持续优化,企业和研究机构可以充分发挥AI大模型的潜力,推动数字化转型。